-> Downloading file:///elastic\elasticsearch-7.1.1/elasticsearch-chosungPlugin-7.1.1.zip
[=================================================] 100%??
Exception in thread "main" java.nio.file.NoSuchFileException: C:\elastic\elasticsearch-7.1.1\plugins\.installing-9326766450384708165\plugin-descriptor.properties
at java.base/sun.nio.fs.WindowsException.translateToIOException(WindowsException.java:85)
at java.base/sun.nio.fs.WindowsException.rethrowAsIOException(WindowsException.java:103)
at java.base/sun.nio.fs.WindowsException.rethrowAsIOException(WindowsException.java:108)
at java.base/sun.nio.fs.WindowsFileSystemProvider.newByteChannel(WindowsFileSystemProvider.java:235)
at java.base/java.nio.file.Files.newByteChannel(Files.java:373)
at java.base/java.nio.file.Files.newByteChannel(Files.java:424)
at java.base/java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:420)
at java.base/java.nio.file.Files.newInputStream(Files.java:158)
at org.elasticsearch.plugins.PluginInfo.readFromProperties(PluginInfo.java:156)
at org.elasticsearch.plugins.InstallPluginCommand.loadPluginInfo(InstallPluginCommand.java:714)
at org.elasticsearch.plugins.InstallPluginCommand.installPlugin(InstallPluginCommand.java:793)
at org.elasticsearch.plugins.InstallPluginCommand.install(InstallPluginCommand.java:776)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:231)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:216)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.plugins.PluginCli.main(PluginCli.java:47)
plugin-descriptor.properties 가 필요한가봐요...
아 이건 뭐지 하고 한참을 찾아보니...
위 글 내용의 ES 버전을 보니 0.17.1...뚜둥!!
정확히 몇 버전 부터 인지는 모르나, plugin 설치시 해당 내용에는 plugin-descriptor.properties 이게 있어야 하더라고요!
파일 이름을 plugin-descriptor.properties로 했어야 했는데 plugin-descrptor.properties로 했더라...는 전설이
(또한 zip압축시 루트에 존재하지 않고 폴더를 하나 지니고 있을 경우 동일한 에러발생)
여튼 이 문제는 지나고 나니!
C:\elastic\elasticsearch-7.1.1\bin>elasticsearch-plugin.bat install file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
-> Downloading file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
[=================================================] 100%??
Exception in thread "main" java.lang.IllegalArgumentException: property [classname] is missing for plugin [chosung-plugin]
at org.elasticsearch.plugins.PluginInfo.readFromProperties(PluginInfo.java:192)
at org.elasticsearch.plugins.InstallPluginCommand.loadPluginInfo(InstallPluginCommand.java:714)
at org.elasticsearch.plugins.InstallPluginCommand.installPlugin(InstallPluginCommand.java:793)
at org.elasticsearch.plugins.InstallPluginCommand.install(InstallPluginCommand.java:776)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:231)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:216)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.plugins.PluginCli.main(PluginCli.java:47)
C:\elastic\elasticsearch-7.1.1\bin>elasticsearch-plugin.bat install file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
-> Downloading file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
[=================================================] 100%??
Exception in thread "main" java.lang.IllegalArgumentException: Unknown properties in plugin descriptor: [plugin]
at org.elasticsearch.plugins.PluginInfo.readFromProperties(PluginInfo.java:233)
at org.elasticsearch.plugins.InstallPluginCommand.loadPluginInfo(InstallPluginCommand.java:714)
at org.elasticsearch.plugins.InstallPluginCommand.installPlugin(InstallPluginCommand.java:793)
at org.elasticsearch.plugins.InstallPluginCommand.install(InstallPluginCommand.java:776)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:231)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:216)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.plugins.PluginCli.main(PluginCli.java:47)
이번에는 해당 프로퍼티 안에 정의된 내용이 문제가 있는 친절한 설명입니다.
1. 플러그인으로 사용될 classname을 지정해야 함.
2. plugin 이라는 프로퍼티는 모르는놈이다...(모르는놈이면 그냥 안쓰면 그만 아닌가...)
여튼 두가지 친절한 로그로 인해 수정 후 다시 시도~
C:\elastic\elasticsearch-7.1.1\bin>elasticsearch-plugin.bat install file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
-> Downloading file:///elastic\elasticsearch-7.1.1/chosung-plugin-1.0.zip
[=================================================] 100%??
Exception in thread "main" java.lang.IllegalStateException: failed to load plugin chosung-plugin due to jar hell
at org.elasticsearch.plugins.PluginsService.checkBundleJarHell(PluginsService.java:524)
at org.elasticsearch.plugins.InstallPluginCommand.jarHellCheck(InstallPluginCommand.java:765)
at org.elasticsearch.plugins.InstallPluginCommand.loadPluginInfo(InstallPluginCommand.java:728)
at org.elasticsearch.plugins.InstallPluginCommand.installPlugin(InstallPluginCommand.java:793)
at org.elasticsearch.plugins.InstallPluginCommand.install(InstallPluginCommand.java:776)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:231)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:216)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.plugins.PluginCli.main(PluginCli.java:47)
Caused by: java.lang.IllegalStateException: jar hell!
"어휴 이건 또 뭐지 jar hell? jar 지옥?ㅋㅋㅋ"
이 부분은 여러글을 찾아보니...대강 짐작이 가서 ...
위에 빌드시 depency 한 luncene jar가 두개 존재하는데...
이게 이미 es에서 존재하고 사용중인거라 필요가 없다는 내용인듯했다.
근데 나는 zip 을 만들때 include로 chosung-plugin-1.0.jar만 지정 했는데도,
이게 들어와 있으니, 영문을 모를 따름... ㅎㅎ
그냥 압축 해제 후 두개의 jar를 포함하지 않은 상태로 다시 zip으로 압축했네요.
(반디집으로 ㅋㅋ)
여튼 이후 플러그인 설치는 잘 된듯 하고!
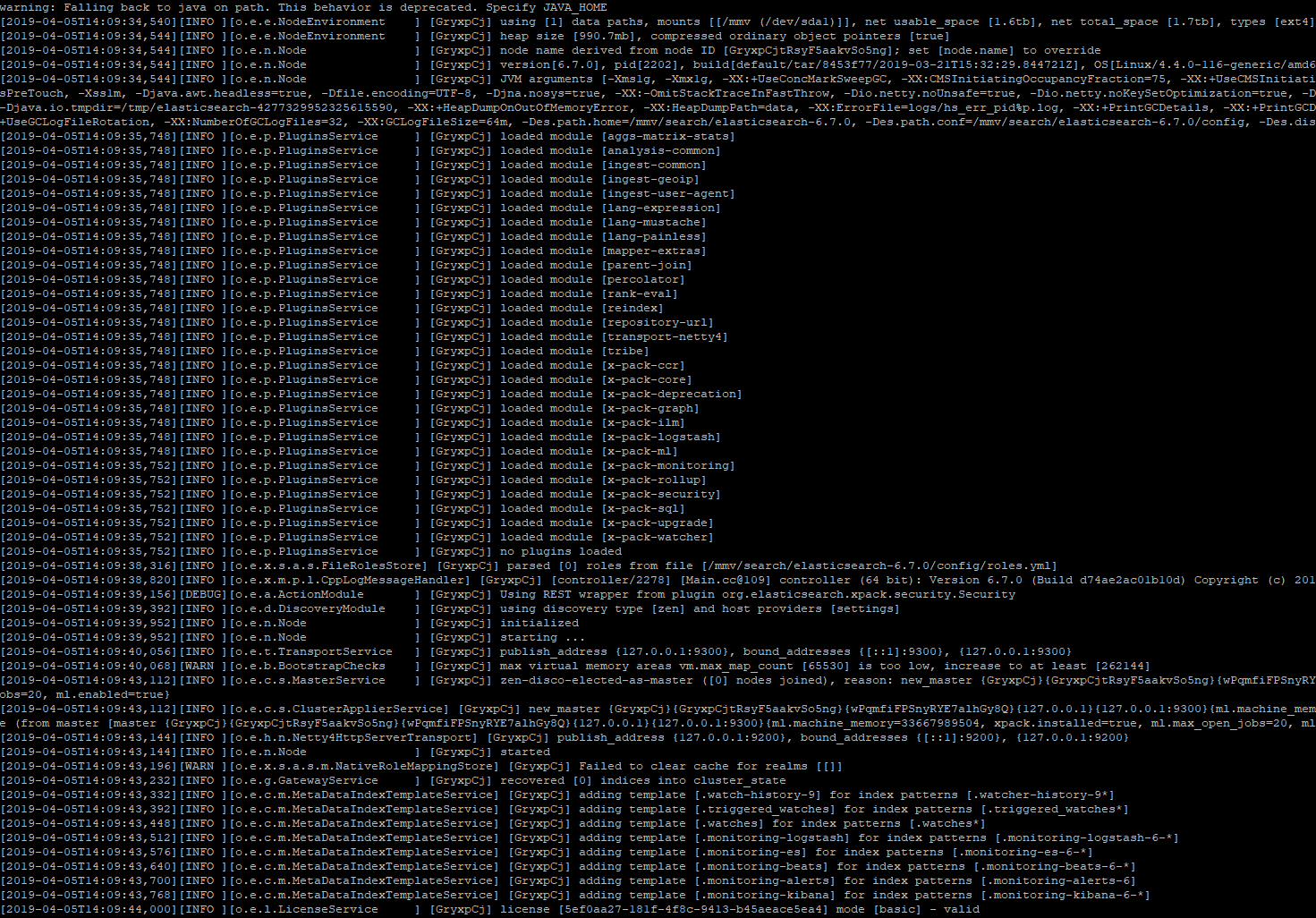
ES를 구동하니...
[2019-08-01T16:46:48,649][INFO ][o.e.e.NodeEnvironment ] [KYN-PC] using [1] data paths, mounts [[(C:)]], net usable_space [91.1gb], net total_space [237.8gb], types [NTFS]
[2019-08-01T16:46:48,668][INFO ][o.e.e.NodeEnvironment ] [KYN-PC] heap size [989.8mb], compressed ordinary object pointers [true]
[2019-08-01T16:46:48,676][INFO ][o.e.n.Node ] [KYN-PC] node name [KYN-PC], node ID [w79MYvdUQguvtunBL1Vrgw], cluster name [elasticsearch]
[2019-08-01T16:46:48,680][INFO ][o.e.n.Node ] [KYN-PC] version[7.1.1], pid[7744], build[default/zip/7a013de/2019-05-23T14:04:00.380842Z], OS[Windows 10/10.0/amd64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/12.0.1/12.0.1+12]
[2019-08-01T16:46:48,685][INFO ][o.e.n.Node ] [KYN-PC] JVM home [C:\elastic\elasticsearch-7.1.1\jdk]
[2019-08-01T16:46:48,687][INFO ][o.e.n.Node ] [KYN-PC] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=C:\Users\comyn\AppData\Local\Temp\elasticsearch, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Djava.locale.providers=COMPAT, -Dio.netty.allocator.type=unpooled, -Delasticsearch, -Des.path.home=C:\elastic\elasticsearch-7.1.1, -Des.path.conf=C:\elastic\elasticsearch-7.1.1\config, -Des.distribution.flavor=default, -Des.distribution.type=zip, -Des.bundled_jd=true]
[2019-08-01T16:46:51,086][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [KYN-PC] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.ClassCastException: class com.mmv.chosung.ChosungPlugin
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124) ~[elasticsearch-cli-7.1.1.jar:7.1.1]
at org.elasticsearch.cli.Command.main(Command.java:90) ~[elasticsearch-cli-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92) ~[elasticsearch-7.1.1.jar:7.1.1]
Caused by: java.lang.ClassCastException: class com.mmv.chosung.ChosungPlugin
at java.lang.Class.asSubclass(Class.java:3646) ~[?:?]
at org.elasticsearch.plugins.PluginsService.loadPluginClass(PluginsService.java:581) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.plugins.PluginsService.loadBundle(PluginsService.java:555) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.plugins.PluginsService.loadBundles(PluginsService.java:471) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.plugins.PluginsService.<init>(PluginsService.java:163) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.node.Node.<init>(Node.java:308) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.node.Node.<init>(Node.java:252) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:211) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:211) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:325) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-7.1.1.jar:7.1.1]
... 6 more
어 classcastexception??
아 위에서 간과한 문제란 비슷한거 같은데...
plugin 클래스 만들때 AbstractModule를 상속받은게 원인이 아닌가 싶더군요.
AbstractModule는 상당히 과거부터 존재했던 클래스인데...용도가 어디인지 모르겠지만...
다른걸 찾아보기로 하고...
두번째 영어 포스팅을 보면 extends Plugin을 사용한걸 확인 할 수 있어요.
문제는 이건 목적에 맞는 인터페이스를 상속받어야 한다는건데...
얘네들 전부가 관련 플러그인...음 이중에 누가 봐도 AnalysisPlugin...이겠지
문제는 또 이걸 어찌 쓰나 찾어봐야해서..
해당 부분은 너무 친절하게 잘 설명 되어있다..ㅎㅎ
AnalysisPlugin.java 상단 코멘트
getCharFilters, getTokenFilters, getTokenizers 등 다양하게 있는데,
나는 토큰필터 니까...그냥 저대로 쓰면 될듯..
그래서 나도 똑같이...
public class ChosungPlugin extends Plugin implements AnalysisPlugin{
@Override
public Map<String, AnalysisProvider<TokenFilterFactory>> getTokenFilters() {
return singletonMap("chosung_filter", JamoTokenFilterFactory::new);
}
}
이렇게 하면 ES안에서 필터이름은 chosung_filter로 사용하면 된겠지비...
어휴 이제 다시 한번 zip파일을 만들고...
플러그인 설치하니... jar hell 다시 오류나고...압축해제 후 루씬 관련 jar 제외한 상태로 다시 압축~~
설치 후 ES 가동!
음 아주 잘 되는구만!
근데 이 필터가 정말 잘 작동할까 의심을 하며, 티몬 김광문님의 블로그에 있는 스크립트를 돌려 보았다!
ES 버전차이가 있어서 아주 약간 수정만 하면 되는데 여튼 잘 된다~!!
이제 이걸 운영서버에 반영만 하면 될듯!!
도움되는 글을 남겨주신 티몬의 김광문님 포함 외국인 형아들에게 감사를 표하며, 그럼 안녕.
spring.io 에 보면 어지간한 저장소와 연결할 수 있는 spring-data 프로젝트가 있더군요!
음...그래서 이것저것 막 삽질해보는데...뭐가 버전이 안맞고 안되고..어휴 ㅠㅠ
maven에서 jar 참조하는 버전을 변경하고 해보는데도..안되고... 어휴 ㅠㅠ
es에 비해 버전업이 너무 느려 ㅠㅠ
es 버전을 7.1.1을 사용하는데...
결국 대강 JPA 흉내라도 내보자는 심산으로...만들어 봐야겠다~~
결심
일단 PO인 도메인(이하 Docu)부터 생성...
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@lombok.ToString
@Document(indexName="zipcode")
public class DocuZipcode implements Serializable{
/**
*
*/
private static final long serialVersionUID = -3670872846932659171L;
@Id
public String buildingControlNumber;
public String lawTownCode;
public String city;
public String ward;
public String town;
public String lee;
public String isMountaion;
public String jibun;
public String jibunSub;
public String roadCode;
public String road;
public String isUnderground;
public String buildingNumber;
public String subBuildingNumber;
public String buildingName;
public String buildingNameDetail;
public String dongNumber;
public String dongCode;
public String dongName;
public String zipcode;
public String zipcodeNumber;
public String massDlvr;
public String moveReasonCode;
public String stdnDate;
public String preRoadName;
public String cityBuildingName;
public String isPublic;
public String newZipCode;
public String idDetailAddr;
public String etc1;
public String etc2;
public String message;
public String path;
public String host;
}
> vi config/elasticsearch.yml
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
제 기억으로는 이 부분을 수정하면 되는 것으로 기억을 합니다.
http.port 는 서버가 실행되는 port를 말하겠죠~?
network.host 는 접속 할 수 있는 IP 대역대를 말하는것 같아요!!
뭐 실 방화벽 및 웹 방화벽 사용하실테니까~~ 저는 그렇기 때문에 network.host 는 0.0.0.0으로 해줄거에요!
그리고 아시겠지만, 앞에 #은 주석이니까 꼭 제거 해주셔야 해요.
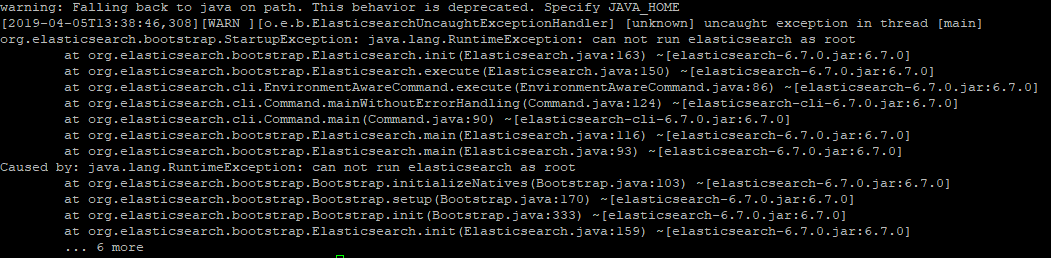
그럼 다시 실행 해보면~~아 또 안되~~~
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
> bash <(curl -s https://bitbucket.org/eunjeon/seunjeon/raw/master/elasticsearch/scripts/downloader.sh) -e 6.7.0 -p 6.1.1.1
...
...
./downloader.sh: line 74: zip: command not found
일단 실행을 했는데, 안되네요. zip이 설치가 안되어 있어서 그렇네요.
뭐 대충 apt-get install zip 하면 설치 되고, 다시 시도 했어요.
임시폴더에 받아서 버전 변경 작업을 하고 현재 작업 폴더로 가져오는 거에요.
아래처럼 실행하면,
> bin/elasticsearch-plugin install file://`pwd`/elasticsearch-analysis-seunjeon-6.1.1.1.zip
warning: Falling back to java on path. This behavior is deprecated. Specify JAVA_HOME
-> Downloading file:///mmv/search/elasticsearch-6.7.0/plugins/elasticsearch-analysis-seunjeon-6.1.1.1.zip
[=================================================] 100%
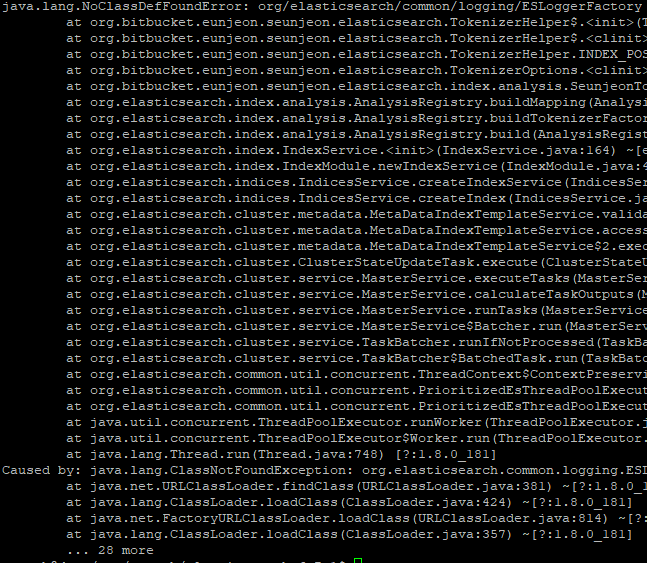
ERROR: This plugin was built with an older plugin structure. Contact the plugin author to remove the intermediate "elasticsearch" directory within the plugin zip.
에러가 나요!
이 플러그인은 예전 방식 구조 라서, zip내에 elasticsearch 폴더를 지우래요.