서비스에서 약 백오십만의 유저에게 알림을 전달하는 새로운 시스템에 대해 이야기를 하다, 어떤 방식으로 이걸 풀어야 하는지 생각하게 됨
API로 받아줄 경우 대상을 매번 추리는데 리소스가 크게 들거라 생각
동시성 모델로 해당 대상 목록을 주기적으로 관리하며 알림을 전달하는건 어떨까 고민하게됨
잘못된 문제 인식 및 커뮤니케이션 오류
동시성 모델로 선형적 자료형을 관리하고, 호출시마다 해당 자료형을 청크로 찍어내어 알림을 전달한다.
예상된 문제는 값복사가 일어나서 메모리 사용량이 늘어날 거라 생각됨.
대상을 추리기 위해서는 값복사 후 청크를 해야하나 vs 값복사 없이 청크를 말까
안해도 된다고 해도 자바는 함수호출시 매개변수 전달로 인해 값복사가 일어나는데, 이건 문제가 아닐까?
체크
오늘 생각하다보니 이게 잘못된거 같다는 생각이 들었고, 자바는 call by value인걸 인지는 하고 있지만, 그게 값복사가 항상 발생하는건 아닌듯 하여 확인하고자 함
과정
우선 아래 코드를 통해 150만개의 대상을 만들고 이걸 리스트에 저장함
val callBySomething = CallBySomething()
val list = callBySomething.list
println("hash=" + System.identityHashCode(list))
for(i in 1500000..3000000){
list.add(BigInteger.valueOf(i.toLong()))
}
그리고 메모리 사용량을 체크
fun getMemoryUsage(): Long {
val runtime = Runtime.getRuntime()
return runtime.totalMemory() - runtime.freeMemory()
}
# 결과
hash=258952499
Memory used by myList: 120 MB
그리고 해당 객체를 매개변수로 사용하는 함수를 콜하여 해시값과 다시 한번 메모리 사용량을 체크
callBySomething(list)
val memoryAfter2 = getMemoryUsage()
println("Memory used by myList: ${(memoryAfter2 - memoryBefore)/1024/1024} MB")
fun callBySomething(list: MutableList<BigInteger>): MutableList<BigInteger> {
println("hash=" + System.identityHashCode(list))
return list
}
# 결과
hash=258952499
Memory used by myList: 120 MB
# 동일한 해시값과 변화없는 메모리 사용량
이번에는 깊은 복사를 해보자
val newList = copy(list)
val memoryAfter3 = getMemoryUsage()
println("Memory used by myList: ${(memoryAfter3 - memoryBefore)/1024/1024} MB")
fun copy(list: MutableList<BigInteger>): List<BigInteger> {
return list.map { BigInteger(it.toByteArray()) }.also {
println("hash=" + System.identityHashCode(it))
}
}
# 결과
hash=1149319664
Memory used by myList: 236 MB
# 당연히 변경된 해시값과 그리고 증가한 메모리양
만약 copy의 코드가 아래와 같다면 list는 새로운 객체를 가리키겠지만, 그 안의 객체는 동일한 객체를 사용하여, 메모리 사용량에 차이가 거의 없음
// 왜냐하면 BigInteger도 객체이기 때문
// 새로운 list를 생성시 기존 BigInteger의 참조를 기반으로 생성
fun copy(list: MutableList<BigInteger>): List<BigInteger> {
return list.map { it }.also {
println("hash=" + System.identityHashCode(it))
}
}
자, 그럼 이제 더 헷갈리는 건, 자바는 분명 call by value인데, 왜 마치 call by reference처럼 보이는걸까?
분명한건 원시형 자료를 전달할때는 값복사를 한다는 점
하지만 그게 아닐 경우에는 값의 참조를 복사하여 전달한다는 점
하지만 그렇다고해서 포인터처럼 값의 참조 자체를 전달하는건 아님
이게 어떤 차이가 있느냐, 아래에서 확인해보자
fun referenceOfValue(list: MutableList<BigInteger>) {
var list2 = list
println("list2 hash=" + System.identityHashCode(list2))
list2 = mutableListOf()
println("list2 hash=" + System.identityHashCode(list2))
println("list=${list.size}")
}
# 결과
list2 hash=258952499
list2 hash=2093631819
list=1500001
일단 코틀린은 매개변수가 불변이라 직접 수정은 못 하기에, 따로 변수에 할당하여 동일한 참조를 같는 변수를 만들어서 수정을 함
만약 참조 자체를 전달하는거라면 해당 참조변수를 재선언 했을대, 참조주소 자체에 값을 할당을 하기에 변화가 일어난다
하지만 자바는 재선언시 참조에 새로운 값을 할당하는게 아니라, 객체를 새로 생성하고 해당 객체의 참조를 재선언하는 필드에 할당하다보니 포인터를 사용하는것과는 차이가 있다
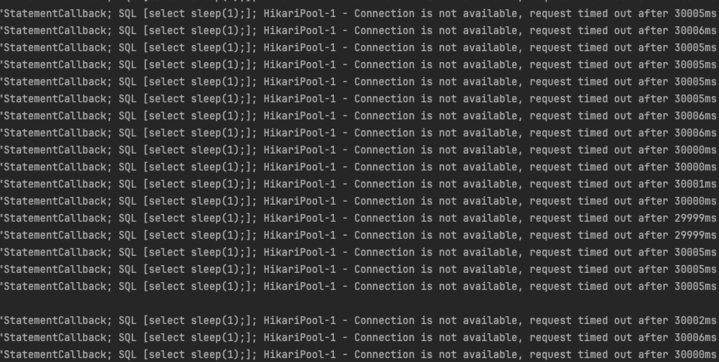
스프링에서 가장 많이 사용되는 Hikari를 사용해서 테스트 해보자 테스트 결과는 아래와 같다. 처참하다.
문제의 원인
기존에 톰캣의 HTTP 커넥터 풀은 최대 스레드 수가 제한되어 있어 DB커넥션 사용에 있어서 적절한 웨이팅 시간 유지가 가능했다. 하지만, 가상스레드를 사용함으로 인해, HTTP 요청을 어마어마하게 받다보니, DB커넥션을 풀에서 받으려 기다리다 기다리다.. 결국 지쳐서 위와 같은 결과를 발생시킨다.
문제의 해결
결과적으로 백프레셔가 필요한데, 이걸 자바에서 동시성에 제공되는 세마포어를 사용하여 해결해 보자.
private lateinit var semaphore: Semaphore
private var maxPoolSize: Int = DEFAULT_MAX_POOL_SIZE
@PostConstruct
fun initSemaphore() {
if (readWriteDataSource.maximumPoolSize > 0) {
maxPoolSize = readWriteDataSource.maximumPoolSize
}
semaphore = Semaphore(maxPoolSize, true)
}
@Pointcut("execution(* com.zaxxer.hikari..HikariDataSource.getConnection(..))")
fun hikariDataSource() = Unit
@Around("hikariDataSource()")
fun around(joinPoint: ProceedingJoinPoint): Any? {
try {
semaphore.acquire()
return joinPoint.proceed()
} finally {
semaphore.release()
}
}
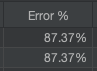
결과
결과는 매우 좋다. 에러율 0%. 실제 요청에 있어서 응답시간은 매우 늦긴하지만, 오류를 딜리버리 하지 않는다는게 핵심
이대로 적용?
이걸 실제로 사용하기에는 어렵다. 단순히 커넥션을 얻는 부분만 래핑이 되어 있기에, 커넥션을 얻은 후 처리 로직이 길어질 경우 문제가 생길 수 있다.(하지만 무난한 적용..)
이걸로 설정하려면 좀 더 괜찮으려나? 아니다. 위 방법 또한 데드락 지점이 생긴다. (남은 자원이 0일때 해당 어노테이션을 사용하는 셀프인보케이션이 아닌 지점에서 모두가 동시에 요청을 한다면, 서로 들고 있는 자원은 릴리즈 되지 않고, 그저 서로 릴리즈 하기만을 기다리는 미친 상황..)
그냥 AOP 코드가 변경이 되야 하는데, 트랜잭션 할당 여부 확인하고, 스레드 확인해서 최초 요청에 대한 부분 기억해 두었다가, 필요하지 않은 경우에는 세마포어 할당을 안받도록 하면 된다. 말이 쉽지 생각보다 복잡..게다가 전파설정이 REQUIRES_NEW 라면? 새로운 커넥션도 할당 받어야 하는 상황까지 고려해야 한다.
안 비밀
테스트한 API는 db에서 sleep을 하는 것과 UNIQUE INDEX를 사용하는 쿼리를 대상으로 테스트 해보았다. sleep이 아닌 일반 쿼리는 pool size를 100으로 했을때, Throughput이 50정도 나오긴 했다. RDB를 사용한다면 성능적인 차이보다는 비용적인 부분에서 이점이 생기긴 할듯! 결정적으로 mysql jdbc의 connectionImpl 클래스를 보면 synchronized 천지라서 스레드 피닝이 발생한다는 점!
자바 환경에서 개발을 한다면, 아마 모르는 분들이 없을 것 같은‘Project Loom’작년 하반기를 핫하게 달군 ‘Virtual Thread’를 과연 운영 환경에서 사용 할 수 있을지? 궁금하여 테스트를 진행 하였습니다. Spring Boot 기준 3.2버전부터 Virtual Thread를 공식적으로 지원한다는 점 참고 부탁 드립니다.
가상 스레드의 장점은 여기저기 검색하면 정말 많이 나오기에 굳이 설명하지 않겠습니다. 기본적으로 OS Thread를 래핑해서 사용하던 자바로서는 Virtual Thread가 스택 영역 메모리를 잘게 나누어 사용하기에, 더욱 많은 Thread를 발행 할 수 있다는 가장 큰 차이만 알고 있다면 괜찮을 것 같습니다.
이 테스트 조차 살짝 뒷북일 수도 있겠지만, 정확하게 맥락을 짚고 사용해야 하지 않을까 해서
지금 이 테스트를 시작하겠다!
Test Point
동시에 들어온 요청이 사용할 수 있는 스레드(OS)보다 많은 상황을 보는 게 핵심
제한된 환경
동시성
Kotlin Coroutine 과 Java Virtual Thread 의 비교
테스트에서는 실제 상황처럼 I/O 병목을 발생시켜 얼마나 많은 요청을 수월하게 진행하는지 확인
Platform Thread가 요청보다 많은 경우에는 당연히 Virtual Thread를 사용하는 이점이 없습니다.
Server2는 최대한 많은 요청을 수행할 수 있도록 Tomcat Thread 수를 200으로 지정하고 코루틴을 사용하였습니다.
Server1로 보내는 동시성 요청은 100으로 제한합니다.
Server1의 톰캣 스레드는 제한하기로 합니다.
호출되는 코드는 아래와 같습니다.
..
return success(ioTest(1) + ioTest(2))
..
private fun ioTest(i: Int): String{
val responseDTO = restClient.get()
.uri("http://localhost:8001/api/test-time")
.accept(MediaType.APPLICATION_JSON)
.retrieve()
.body(InternalApiResponseDTO::class.java)
val data:String = responseDTO!!.data as String
return data
}
테스트 진행
Virtual Off & Tomcat Thread 20 & Blocking
결과 ( 평균 응답 시간 2136.644 ms )
Concurrency Level: 100
Time taken for tests: 21.366 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 440000 bytes
HTML transferred: 76000 bytes
Requests per second: 46.80 [#/sec] (mean)
Time per request: 2136.644 [ms] (mean)
Time per request: 21.366 [ms] (mean, across all concurrent requests)
Transfer rate: 20.11 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 4.5 0 34
Processing: 423 1999 314.4 2072 2184
Waiting: 423 1998 314.4 2072 2184
Total: 427 2000 311.1 2073 2185
Percentage of the requests served within a certain time (ms)
50% 2073
66% 2089
75% 2095
80% 2107
90% 2125
95% 2146
98% 2154
99% 2161
100% 2185 (longest request)
Virtual Off & Tomcat Thread 50 & Blocking
결과 ( 평균 응답 시간 903.952 ms )
Concurrency Level: 100
Time taken for tests: 9.040 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 460000 bytes
HTML transferred: 76000 bytes
Requests per second: 110.63 [#/sec] (mean)
Time per request: 903.952 [ms] (mean)
Time per request: 9.040 [ms] (mean, across all concurrent requests)
Transfer rate: 49.69 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 1.5 1 10
Processing: 421 815 86.8 832 872
Waiting: 420 814 86.8 831 872
Total: 424 817 86.5 834 873
Percentage of the requests served within a certain time (ms)
50% 834
66% 839
75% 842
80% 843
90% 852
95% 865
98% 868
99% 869
100% 873 (longest request)
Virtual On & Blocking
결과 ( 평균 응답 시간 500.406 ms )
Concurrency Level: 100
Time taken for tests: 5.004 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 460000 bytes
HTML transferred: 76000 bytes
Requests per second: 199.84 [#/sec] (mean)
Time per request: 500.406 [ms] (mean)
Time per request: 5.004 [ms] (mean, across all concurrent requests)
Transfer rate: 89.77 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 1.0 1 6
Processing: 407 426 21.8 420 725
Waiting: 406 426 21.6 419 712
Total: 407 428 22.2 421 725
Percentage of the requests served within a certain time (ms)
50% 421
66% 425
75% 427
80% 430
90% 455
95% 478
98% 494
99% 501
100% 725 (longest request)
Platform Thread vs Virtual Thread
예상했던 결과이며, Tomcat Thread만 늘려주어도 확실히 응답 속도가 개선됨을 알 수 있습니다. 하지만, Tomcat Thread 는 설정에 따라 다르겠지만, 적게는 0.5MB 많게는 2MB 가량의 메모리를 사용하여 머신의 메모리 크기에 대비에 스레드 발행 수가 제한되기 마련입니다. 반대로 Virtual Thread의 경우 작은 양의 Stack Memory를 사용하기에 많은 양의 Thread를 발행 할 수 있으며, JVM에서 I/O Blocking 구간을 알아서 잡아내어 결과에서 알 수 있듯이 Virtual Thread를 사용하는게 압도적으로 빠릅니다. I/O 발생 시 ForkJoinPool이 Virtual Thread의 작업을 효율적으로 관리하여 주기 때문입니다.
그럼 이제 코루틴과의 비교를 해보겠습니다.
우선 가상스레드 안에서 가상스레드를 만들어 Join을 하는 형태의 코드
val future1 = CompletableFuture.supplyAsync({
ioTest(1)
}, executorService)
val future2 = CompletableFuture.supplyAsync({
ioTest(2)
}, executorService)
return success(future1.get() + future2.get())
그리고 webClient를 사용한 Coroutine 코드
suspend fun ioTestCoroutine(): ResponseDTO<String> = withContext(Dispatchers.IO) {
val deferred1 = ioTestAwait(1)
val deferred2 = ioTestAwait(2)
success(deferred1.await() + deferred2.await())
}
...
private suspend fun ioTestAwait(i: Int): Deferred<String> {
return CoroutineScope(Dispatchers.IO).async {
val responseDTO = webClient
.get()
.uri("http://localhost:8001/api/test-time")
.retrieve()
.bodyToMono(InternalApiResponseDTO::class.java)
.awaitSingle()
responseDTO!!.data as String
}
}
Virtual On & Use Virtual Thread Join
결과 ( 평균 응답 시간 241.797 ms )
Concurrency Level: 100
Time taken for tests: 2.418 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 440000 bytes
HTML transferred: 76000 bytes
Requests per second: 413.57 [#/sec] (mean)
Time per request: 241.797 [ms] (mean)
Time per request: 2.418 [ms] (mean, across all concurrent requests)
Transfer rate: 177.71 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 1.2 1 20
Processing: 202 214 11.3 209 256
Waiting: 202 213 11.2 209 255
Total: 202 215 11.8 211 258
Percentage of the requests served within a certain time (ms)
50% 211
66% 213
75% 217
80% 222
90% 231
95% 237
98% 253
99% 256
100% 258 (longest request)
Virtual Off & WebClient & Use Coroutine
결과 ( 평균 응답 시간 244.610 )
Concurrency Level: 100
Time taken for tests: 2.446 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 440000 bytes
HTML transferred: 76000 bytes
Requests per second: 408.81 [#/sec] (mean)
Time per request: 244.610 [ms] (mean)
Time per request: 2.446 [ms] (mean, across all concurrent requests)
Transfer rate: 175.66 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 1.1 0 6
Processing: 202 219 8.7 220 246
Waiting: 202 218 8.7 219 246
Total: 202 220 9.1 221 247
Percentage of the requests served within a certain time (ms)
50% 221
66% 225
75% 227
80% 228
90% 230
95% 233
98% 235
99% 239
100% 247 (longest request)
Virtual Thread vs. Coroutine
이것도 어느정도 예상한 결과이긴 합니다. 둘은 체감상 차이가 없으며, 실제 성능은 매 테스트마다 아주 조금씩 달랐습니다.또한 현재 기재된 테스트 요청은 모두 병렬 요청이었는데, 하나의 가상 스레드 내에서 Blocking으로 인해 스레드를 스위칭 하는 성능차이 또한 궁금해서 테스트를 진행했지만, 이것 또한 별반 차이가 없어서 작성하지는 않았습니다.
그래서? 뭐를 어떻게 써야하죠?
Spring MVC에서 적은 노력으로 퍼포먼스를 올리기에는 Virtual Thread가 좋아 보입니다.
Coroutine의 경우 중단 가능한 suspend 함수를 작성해야 하는데, Virtual Thread는 그러한 노력 없이 알아서 감지가 되니 편합니다.
아님 뭐 메서드 내 필드를 이용해서 이렇게 바꿀까? 이것도 뭐 크게 다른건 없다고 느끼는데, 그렇다고 싱글톤 기반의 빈에서 클래스 필드를 맘대로 교체할 수도 없는 노릇이고,
좀 더 고차원 레이어에 영향이 안가는 방법의 코드를 작성 할 수는 없을까?
있다, Enum과 Provider를 사용하면 된다. Spring Container는 등록된 모든 Bean에 대한 제어가 가능하다. 일단 등록되어 있으니 가져오는 것도 가능하다. 구조적으로는 위에 if문을 사용하는 것과 차이가 없지만,
적어도 인터페이스를 호출 하는 부분을 타입이나, 유형 때문에 바꿀 일은 없을 거다.
예시 코드 들어간다.
참고로 제 코드가 좋은 코드는 아닙니다용..제발...
public interface PayService {
void pay();
}
private class PayKakaoService implements PayService {
@Override
public void pay() {
}
}
private class PaySamsungService implements PayService {
@Override
public void pay() {
}
}
private class PayNaverService implements PayService {
@Override
public void pay() {
}
}
// private PayService payKakaoService;
// private PayService paySamsungService;
// private PayService payNaverService;
@Getter
@RequiredArgsConstructor
public enum PayType {
Kakao(PayKakaoService.class), Samsung(PaySamsungService.class), Naver(
PayNaverService.class);
private final Class<? extends PayService> clazz;
}
public class PayServiceProvider {
private static ApplicationContext applicationContext;
private static Map<PayType, Class<? extends PayService>> payServiceMap = new HashMap<>();
static {
for (PayType payType : PayType.values()) {
payServiceMap.put(payType, payType.getClazz());
}
}
public static PayService service(PayType payType) throws Exception {
Class<? extends PayService> payServiceClass = payServiceMap.get(payType);
if (payServiceClass == null) {
throw new Exception();
}
return applicationContext.getBean(payServiceClass);
}
}
@PostMapping("/payment")
public ResponseEntity<?> pay(PayType payType) throws Exception {
// PayService ps = null;
//
// if (payType == PayType.Kakao) {
// ps = payKakaoService;
// }
//
// if (payType == PayType.Samsung) {
// ps = paySamsungService;
// }
//
// if (payType == PayType.Naver) {
// ps = payNaverService;
// }
//
// ps.pay();
PayServiceProvider.service(payType).pay();
return ResponseEntity.ok().build();
}
// 실행
void callPayTest() throws Exception {
this.pay(PayType.Samsung);
}
일단, 해당 코드는 provider에서 사용하는 applicationContext에 대한 주입이 없긴하다. 요건 이제 @PostConstruct를 사용해서 주입하면 되긴합니다요. 물론 주입하는 함수도 provider에 static으로 만들어 줘야 합니다. (대충 읽고 코드만 복붙하면 안되게 하려는 함정...)