# ev 6.7.0에 pv 6.1.1.1은 설치는 가능한대, 작동이 안되요! 아래 글은 삽질 과정이 포함되어 있습니다!
# 6.7.0으로 시도했다가 안되서 6.1.4로 재시도 하였습니다.
# ES 7은 프로덕션모드로 실행하기 위해서 discovery.seed_hosts와 cluster.initial_master_nodes를 지정해야해요.
찾아보자 찾아보자~~
1. ElasticSearch 설치
일단 현재 ES 최신버전은 6.7.0
https://www.elastic.co/kr/downloads/elasticsearch
저장소 등록 후 apt-get 또는 deb를 내려받아서 패키지 설치를 CentOS라면 rpm 설치 하시면 되겠지용?
하지만, 저는
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.tar.gz
위 링크를 받아서 그냥 압축 풀어서 사용할게요.
그냥 압축풀고 실행만 하면 되서 어려울게 없어요.
뭔가 실수 했을때 지우기도 편하고 ㅎㅎ(이게 핵심)
> wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.tar.gz
> tar -xvf elasticsearch-6.7.0.tar.gz위와 같이 명령어를 입력하면
아래처럼 파일 하나 받고, 압축 풀어서 폴더도 생기겠죠?
결과
> cd elasticsearch-6.7.0폴더 내용을 살펴 볼까용?
결과
아~ /bin은 실행파일 있을거고, /config는 설정관련, /logs는 로그가 쌓이겠다~ 그죠?
/bin
/config
이제 어떻게 실행하는지...
공식홈을 한번 볼까요?
https://www.elastic.co/kr/downloads/elasticsearch
아주 친절하죠~
시키는대로 해보죠!
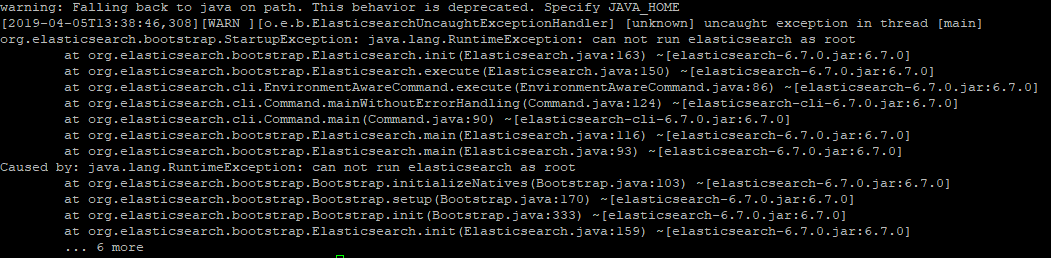
> bin/elasticsearch앗! 이럴수가!
저는 루트 계정이라 실행이 안되네요 ㅠ_ㅠ
계정을 변경해야겠어요.
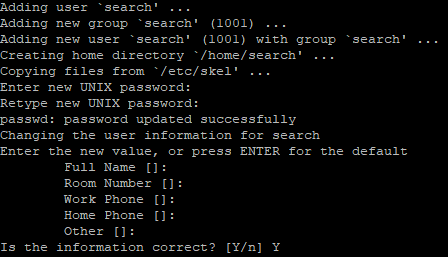
> adduser search
search라는 이름의 계정을 만들었어요!
(그리고 필요할지 모르니 sudo 권한을 주세요!)
이제 폴더와 파일의 소유권을 search계정이 사용 할 수 있게 만들어 봅시다.
일단 상위 폴더로 먼저 이동 하고...
> cd ..
> chown -R search:search elasticsearch-6.7.0
> ll소유자 및 그룹 변경 완료!
자 그럼 이제 계정을 search로 갈아타서 실행해볼게요!
> su - search
> bin/elasticsearch실행결과
뭐라고 말이 많은데 실행이 된거 같죠? 첫 줄에 경고는 찾아봐야 겠네요.
(위 상태에서 Ctrl+c 누르면 stop이 됩니다!)
앗 그리고 중요한거! 자바가 설치되어 있어야해요! 1.8버전 이상의 자바요!
(이걸 이제서야 말하다니!!)
오라클 자바는 구독해야하니까...(맞죠? 요즘 오라클자바쓰는분들 돈내고 쓰시는거 맞죠?)
지금 설치하고 있는 서버에는 zulu8-openjdk 설치되어 있습니다~
일단 기본 port는 9200일테니, 한번 웹으로 접속 해볼게요!
ip가 노출되서...여튼 접속이 안되요! 왜 안될까요?!
그럼 정상적으로 실행이 되어 있는지 확인 이라도 해볼까요?
> curl http://localhost:9200
{
"name" : "GryxpCj",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "_N9jkX5iTfKrYEYBfpIzjw",
"version" : {
"number" : "6.7.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "8453f77",
"build_date" : "2019-03-21T15:32:29.844721Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
와 아주 정상적이에요!
근데 왜 웹으로는 안될까요?
접속이 왜 안되는지 확인 해봐야겠어요.
아마 설정 부분일거 같은데요~~
> vi config/elasticsearch.yml
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
제 기억으로는 이 부분을 수정하면 되는 것으로 기억을 합니다.
http.port 는 서버가 실행되는 port를 말하겠죠~?
network.host 는 접속 할 수 있는 IP 대역대를 말하는것 같아요!!
뭐 실 방화벽 및 웹 방화벽 사용하실테니까~~ 저는 그렇기 때문에 network.host 는 0.0.0.0 으로 해줄거에요!
그리고 아시겠지만, 앞에 #은 주석이니까 꼭 제거 해주셔야 해요.
그럼 다시 실행 해보면~~아 또 안되~~~
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]영어는 잘 못 하지만, 이 정도는 읽을 수 있찌!!
가상 메모리 영역이 최소 262144 정도는 되야 한다는 얘긴데..
레퍼런스 문서를 찾아보면...
https://www.elastic.co/guide/en/elasticsearch/reference/current/system-config.html
Important System Configuration | Elasticsearch Reference [6.7] | Elastic
Important System Configurationedit Ideally, Elasticsearch should run alone on a server and use all of the resources available to it. In order to do so, you need to configure your operating system to allow the user running Elasticsearch to access more resou
www.elastic.co
elasticsearch는 기본적으로 개발 모드로 작동을 하는데 네트워크 구성을 적용하면 프로덕션 모드로 작동을 한다고 하네요. 이 과정에서 아래의 것들중 부족한게 있으면 안된다고...
위 링크 들어가서 하나하나 다음 링크를 눌러보면..
https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
Virtual memory | Elasticsearch Reference [6.7] | Elastic
Elasticsearch uses a mmapfs directory by default to store its indices. The default operating system limits on mmap counts is likely to be too low, which may result in out of memory exceptions. On Linux, you can increase the limits by running the following
www.elastic.co
요기로 들어가지는데요!
아래 명령어를 실행하라고 하네요!
> sysctl -w vm.max_map_count=262144일단 위 사항 때문에 실행이 안되니까, 위 명령어를 실행 후 다시 한번 bin/elasticsearch를 해보겠어요!
와 드디어 실행이! 되었어요!
로그에서 달라진 점이 있다면 publish_address와 bound_address가 달라졌다는거...
이제 웹에서 접속이 되는지 볼게요!
사무실에 개발서버로 비치된 내부IP는 192.168.0.18 입니다.
그래서 http://192.168.0.18:9200/ 로 접속.
접속이 잘 되네요!
2. 은전한닢 플러그인 적용 이제 은전한닢을...적용 해볼까요.
(너무 길어요 ㅠㅠ. 언제 끝날까 이 포스팅..)
일단 너무 고마운 은전한닢 프로젝트 블로그로 가볼게요.
http://eunjeon.blogspot.com/
은전한닢 프로젝트
은전한닢 프로젝트: 오픈 소스 한국어 / 한글 형태소 분석기 Lucene/Solr, ElasticSearch 플러그인
eunjeon.blogspot.com
(플러그인 개발이 주업이 아닐텐데 이런 수고스런 일을 해주시다니, 정말 감사합니다.ㅠㅠ)
글을 좀 내려보니 이런 글이 있어요!
http://eunjeon.blogspot.com/2017/06/elasticsearch-anaysis-seunjeon.html
elasticsearch-anaysis-seunjeon 다운로더
은전한닢 프로젝트: 오픈 소스 한국어 / 한글 형태소 분석기 Lucene/Solr, ElasticSearch 플러그인
eunjeon.blogspot.com
참 감사합니다 ㅠ
예전에 ES 버전에 맞춰서 은전한닢을 설치했던 것이 기억에 납니다.
그렇기 때문에 이러한 작업을 해주신게 아닐까 해요!
설치한 ES 는 6.7.0
elasticsearch-anaysis-seunjeon은 6.1.1.1 입니다
plugin download 명령은
bash <(curl -s https://bitbucket.org/eunjeon/seunjeon/raw/master/elasticsearch/scripts/downloader.sh) -e 6.7.0 -p 6.1.1.1
이렇게 수정이 되겠죠?
-e 는 es버전 -p는 plugin버전
downloader.sh 내용이 궁금해서 받아서 열어 보았습니다.
위에 설명해주신 내용과 별반 다를게 없는 내용이었습니다.
> bash <(curl -s https://bitbucket.org/eunjeon/seunjeon/raw/master/elasticsearch/scripts/downloader.sh) -e 6.7.0 -p 6.1.1.1
...
...
./downloader.sh: line 74: zip: command not found
일단 실행을 했는데, 안되네요. zip이 설치가 안되어 있어서 그렇네요.
뭐 대충 apt-get install zip 하면 설치 되고, 다시 시도 했어요.
임시폴더에 받아서 버전 변경 작업을 하고 현재 작업 폴더로 가져오는 거에요.
아래처럼 실행하면,
> bin/elasticsearch-plugin install file://`pwd`/elasticsearch-analysis-seunjeon-6.1.1.1.zip
warning: Falling back to java on path. This behavior is deprecated. Specify JAVA_HOME
-> Downloading file:///mmv/search/elasticsearch-6.7.0/plugins/elasticsearch-analysis-seunjeon-6.1.1.1.zip
[=================================================] 100%
ERROR: This plugin was built with an older plugin structure. Contact the plugin author to remove the intermediate "elasticsearch" directory within the plugin zip.에러가 나요!
이 플러그인은 예전 방식 구조 라서, zip내에 elasticsearch 폴더를 지우래요.
압축 해제 후 필요한 파일만 포함해서 재압축 해야겠어요.
그리고 다시 실행!
성공적으로 설치 되었네요~!
ES를 재기동 하면
[2019-04-05T17:34:46,792][INFO ][o.e.p.PluginsService ] [eC7q10w] loaded plugin [analysis-seunjeon]기존 플러그인이 없다고 했었는데 위 처럼 변경 됩니다.
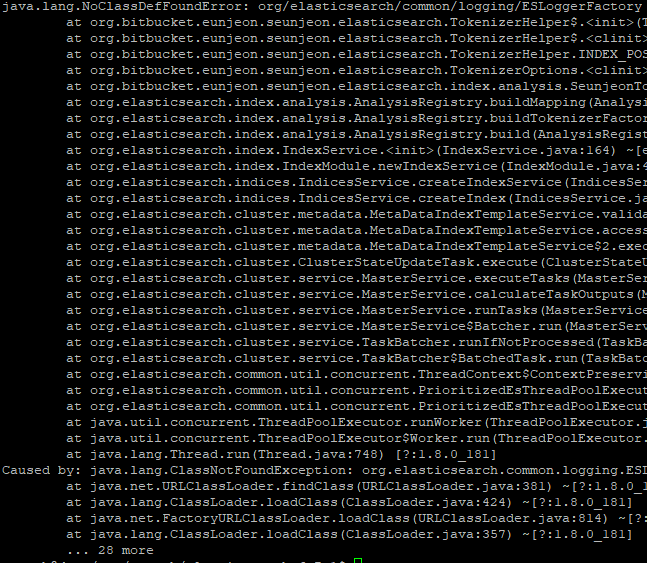
복병은 따로 있었네요 ^^;
SeunjeonTokenizerFactory.java:25에서 없는 클래스를 찾나봐요 ㅠㅠ
찾아보니 6.1.4까지만 해도 있던 놈이..ㅠㅠ
6.2.0에 흔적도 없이 사라짐..ㅠㅠ
아 이럴수가 ㅠ_ㅠ....
ES 6.1.4로 다시 설치해야겠죠?!
> wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.4.tar.gz
> tar -xvf elasticsearch-6.1.4.tar.gz
> bash <(curl -s https://bitbucket.org/eunjeon/seunjeon/raw/master/elasticsearch/scripts/downloader.sh) -e 6.1.4 -p 6.1.1.1
> bin/elasticsearch-plugin install file://`pwd`/elasticsearch-analysis-seunjeon-6.1.1.1.zip
그리고 테스트 스크립트를 돌려보면~!
아주 잘 작동 되는걸 확인 할 수 있습니다.ㅠ_ㅠ
삽질 아닌 삽질을 하며, 여기까지 왔네요.
도움 되셨으면 좋겠어용~~~
오늘도 도움주신 Elastic Stack 관계자 및 은전한닢 그리고 한글형태소 분석기를 위해 애쓰는분들 감사드립니다.
추가글)
실행과 종료에 대한 간단한 스크립트 추가 하도록 할게요!
이전 버전 elasticsearch에 사용되던 스크립트인데, 책에서 참고한 내용 입니다.
> echo 'bin/elasticsearch -d -p es.pid' > start.sh
> echo 'kill `cat es.pid`' > stop.sh
> chmod 755 start.sh stop.sh
# 위키북스 시작하세요 엘라스틱서치! 에서 발췌